LinkedIn 代面 2026 | 真实面经:数据流中位数 + StatsFinder 设计 + 行为面试
2026 年的 LinkedIn 技术面试依然保持着极高的工程标准——算法深度、系统设计能力、行为素养三位一体。本文将完整拆解一场真实 LinkedIn 面试的三轮考察内容,涵盖 数据流中位数的双堆最优解、StatsFinder 统计服务类的 OOD 设计,以及 Behavioral 行为面试的实战要点。
面试结构概览
| 轮次 | 类型 | 核心考察点 |
|---|---|---|
| 第一轮 | 经典算法 | 数据流中的中位数 (Median of a Data Stream),双堆法实现与 Follow-up |
| 第二轮 | 系统设计 (OOD) | StatsFinder 类设计,多指标统计 + 撤回操作,高内聚可复用 |
| 第三轮 | Behavioral | 行为面试,Recruiter 主导,STAR 法则 |
第一轮:经典算法题 — 数据流中的中位数
题目描述
设计一个数据结构,支持以下两种操作:
addNum(num)— 从数据流中添加一个整数findMedian()— 返回当前所有已添加数字的中位数
中位数的定义:
- 若元素个数为奇数,中位数为排序后正中间的数
- 若元素个数为偶数,中位数为排序后中间两个数的平均值
约束条件:findMedian() 的时间复杂度要求为 O(log n) 或更优,而非每次重新排序的 O(n log n)。
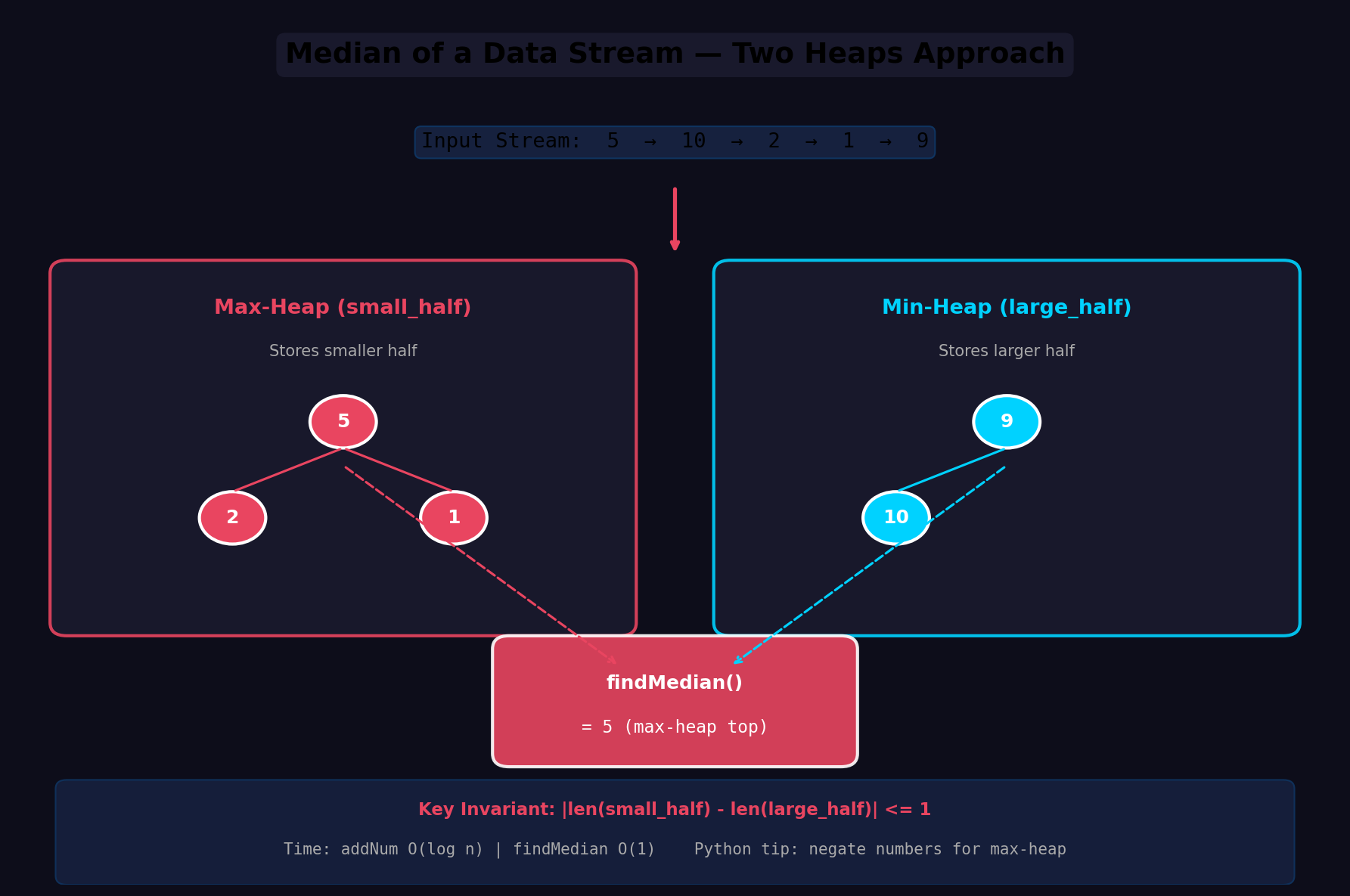
最优解:双堆法 (Two Heaps)
核心思想是将数据流分为较小的一半和较大的一半,分别用堆维护:
- 最大堆
small_half:存储较小一半的数字,堆顶是该半的最大值 - 最小堆
large_half:存储较大一半的数字,堆顶是该半的最小值
平衡约束:两个堆的大小相等,或最多相差 1。
操作逻辑
addNum(num) 的插入策略:
- 将新数字先推入
small_half(最大堆) - 将
small_half的堆顶弹出,推入large_half(最小堆)—— 确保所有进入large_half的数都不小于small_half中的数 - 若
large_half比small_half多出一个以上元素,则将large_half的堆顶弹出,推回small_half—— 恢复平衡
findMedian() 的读取策略:
- 两堆大小相等 → 中位数 =
(small_half 堆顶 + large_half 堆顶) / 2 - 一堆多一个 → 中位数 = 元素更多那一堆的堆顶
完整 Python 实现
import heapq
class MedianFinder:
"""
双堆法求解数据流中位数。
small_half: 最大堆(Python 用小顶堆模拟,存入相反数),存较小一半
large_half: 最小堆,存较大一半
"""
def __init__(self):
self.small_half = [] # 最大堆(存负数模拟)
self.large_half = [] # 最小堆
def addNum(self, num: int) -> None:
# 第 1 步:推入最大堆(用负数模拟)
heapq.heappush(self.small_half, -num)
# 第 2 步:将最大堆的最大值移到最小堆,确保 large_half 的所有值 >= small_half
moved = -heapq.heappop(self.small_half)
heapq.heappush(self.large_half, moved)
# 第 3 步:平衡两堆大小,保证 len(large_half) <= len(small_half) + 1
if len(self.small_half) < len(self.large_half):
moved_back = heapq.heappop(self.large_half)
heapq.heappush(self.small_half, -moved_back)
def findMedian(self) -> float:
if len(self.small_half) > len(self.large_half):
return float(-self.small_half[0])
elif len(self.large_half) > len(self.small_half):
return float(self.large_half[0])
else:
return (-self.small_half[0] + self.large_half[0]) / 2.0
# ===== 使用示例 =====
mf = MedianFinder()
mf.addNum(1)
mf.addNum(2)
print(mf.findMedian()) # 1.5
mf.addNum(3)
print(mf.findMedian()) # 2.0复杂度分析
addNum: O(log n) — 两次堆 push/pop 操作findMedian: O(1) — 直接读取堆顶- 空间复杂度: O(n) — 存储全部 n 个元素
Follow-up 1:增加 removeNum(num) — 懒删除 (Lazy Removal)
面试官进一步追问:如果数据流不仅需要插入,还需要支持 删除任意一个已存在的数,该如何改造?
暴力方案的缺陷
直接从堆中删除指定元素需要 O(n) 遍历,破坏堆结构的对数级优势。
懒删除技术
核心思路:不立即从堆中物理移除元素,而是用哈希表标记"待删除"状态。在堆顶弹出时检查标记,若已被标记则跳过并继续弹出。
import heapq
from collections import defaultdict
class MedianFinderWithRemove:
"""
支持 addNum、removeNum、findMedian 的数据流中位数结构。
采用懒删除 (Lazy Removal) 策略:
- remove_set 记录待删除的数字及其出现次数
- _balance 内部方法在堆顶遇到已标记删除的元素时自动清理
"""
def __init__(self):
self.small_half = [] # 最大堆(负数模拟)
self.large_half = [] # 最小堆
self.small_size = 0 # small_half 有效元素数量
self.large_size = 0 # large_half 有效元素数量
self.remove_set = defaultdict(int) # {num: count} 待删除计数
def _clean_small(self):
while self.small_half and -self.small_half[0] in self.remove_set:
num = -heapq.heappop(self.small_half)
self.remove_set[num] -= 1
if self.remove_set[num] == 0:
del self.remove_set[num]
self.small_size -= 1
def _clean_large(self):
while self.large_half and self.large_half[0] in self.remove_set:
num = heapq.heappop(self.large_half)
self.remove_set[num] -= 1
if self.remove_set[num] == 0:
del self.remove_set[num]
self.large_size -= 1
def _balance(self):
"""确保两堆大小差值不超过 1"""
while self.small_size > self.large_size + 1:
self._clean_small()
moved = -heapq.heappop(self.small_half)
self.small_size -= 1
heapq.heappush(self.large_half, moved)
self.large_size += 1
while self.large_size > self.small_size + 1:
self._clean_large()
moved = heapq.heappop(self.large_half)
self.large_size -= 1
heapq.heappush(self.small_half, -moved)
self.small_size += 1
def addNum(self, num: int) -> None:
if num in self.remove_set and self.remove_set[num] > 0:
# 如果这个数之前被标记为删除,抵消一次删除标记
self.remove_set[num] -= 1
if self.remove_set[num] == 0:
del self.remove_set[num]
self.small_size += 1
heapq.heappush(self.small_half, -num)
else:
heapq.heappush(self.small_half, -num)
self.small_size += 1
self._balance()
def removeNum(self, num: int) -> bool:
"""尝试删除一个数,返回是否成功删除"""
# 判断 num 在哪个堆中(检查堆顶或标记)
self._clean_small()
self._clean_large()
# 策略:标记为待删除,后续 pop 时自动清理
if (self.small_half and -self.small_half[0] == num) or \
(self.large_half and self.large_half[0] == num):
# 堆顶就是目标,直接弹出
if -self.small_half[0] == num:
heapq.heappop(self.small_half)
self.small_size -= 1
else:
heapq.heappop(self.large_half)
self.large_size -= 1
else:
# 目标不在堆顶,标记懒删除
# 需要确定 num 在哪个堆中
if self.small_half and num <= -self.small_half[0]:
self.large_size -= 1 # 实际在 small 中
self.small_size -= 1
else:
self.large_size -= 1
self.remove_set[num] += 1
self._balance()
return True
def findMedian(self) -> float:
self._clean_small()
self._clean_large()
total = self.small_size + self.large_size
if total == 0:
raise ValueError("No numbers in the stream")
if total % 2 == 1:
if self.small_size > self.large_size:
return float(-self.small_half[0])
else:
return float(self.large_half[0])
else:
return (-self.small_half[0] + self.large_half[0]) / 2.0懒删除的复杂度:
removeNum: O(log n) 均摊 — 标记操作 O(1),平衡操作 O(log n)findMedian: O(log n) 均摊 — 清理堆顶的惰性删除元素可能触发多次 pop,但每个元素最多被 pop 一次- 空间:哈希表额外 O(k),k 为待删除元素种类
Follow-up 2:并发处理 — 多线程安全
如果 MedianFinder 需要被多个线程同时调用,如何保证线程安全?
方案:全局锁 (Mutex)
import threading
import heapq
class ConcurrentMedianFinder:
"""
支持并发访问的数据流中位数结构。
使用全局互斥锁 (threading.Lock) 保护所有共享状态。
"""
def __init__(self):
self.small_half = []
self.large_half = []
self._lock = threading.Lock()
def addNum(self, num: int) -> None:
with self._lock:
# 所有堆操作在锁内执行
heapq.heappush(self.small_half, -num)
moved = -heapq.heappop(self.small_half)
heapq.heappush(self.large_half, moved)
if len(self.small_half) < len(self.large_half):
moved_back = heapq.heappop(self.large_half)
heapq.heappush(self.small_half, -moved_back)
def findMedian(self) -> float:
with self._lock:
if len(self.small_half) > len(self.large_half):
return float(-self.small_half[0])
elif len(self.large_half) > len(self.small_half):
return float(self.large_half[0])
else:
return (-self.small_half[0] + self.large_half[0]) / 2.0关键讨论点:
threading.Lock是互斥锁,确保同一时刻只有一个线程执行addNum或findMedian- 读操作
findMedian虽然只是读取堆顶,但仍然需要加锁,因为另一个线程可能正在修改堆结构 - 若读多写少场景,可考虑
threading.RLock或读写锁 (threading.RWLock的第三方实现) 进一步优化
第二轮:设计 — 实现 StatsFinder 类
题目描述
设计一个 StatsFinder 类,支持以下操作:
addNum(num)— 添加一个整数getMax()— 返回当前最大值getMin()— 返回当前最小值getMedian()— 返回中位数withdrawLatest()— 撤回最近一次添加的数(类似"撤销"操作)
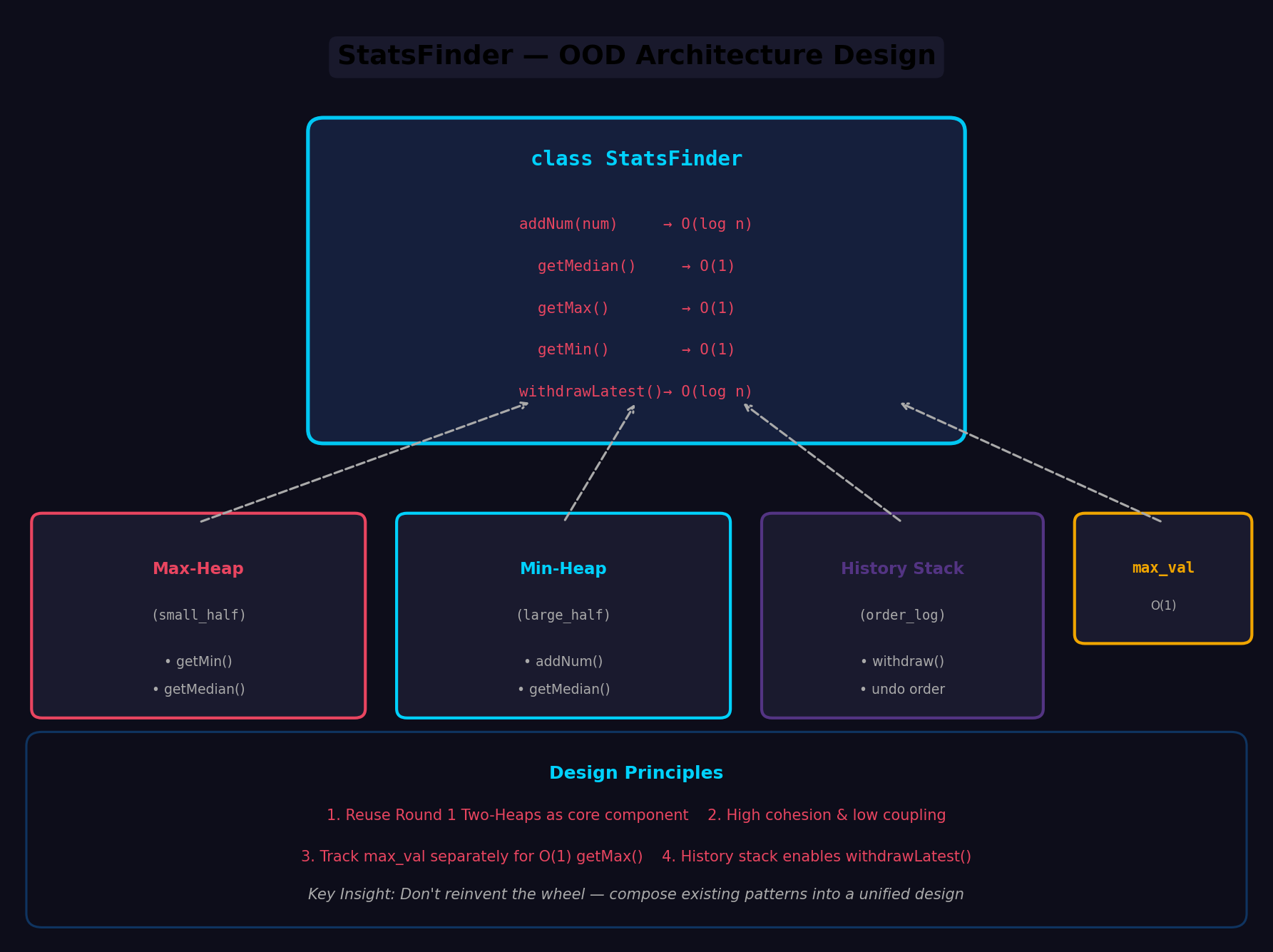
设计思路
这是一个典型的 OOD (面向对象设计) 题目。核心挑战在于如何复用第一轮的双堆结构,同时高效支持多指标查询和撤回操作。
架构决策
- 复用 MedianFinder 的双堆结构:中位数查询直接继承第一轮的最优解
- 额外维护全局最小堆和最大堆:用于 O(1) 获取 min/max
- 操作栈 (History Stack):记录每次
addNum操作的元数据,支持 O(1) 撤回 - 懒删除同步:所有删除操作通过统一的懒删除机制跨堆协调
完整实现
import heapq
from collections import defaultdict
from typing import List, Optional, Tuple
class StatsFinder:
"""
多功能统计数据结构,支持 add、min、max、median、withdraw。
设计原则:
- 复用双堆中位数结构
- 操作日志 + 懒删除实现 O(1) 撤回
- 高内聚、低耦合的 OOD 设计
"""
def __init__(self):
# 中位数双堆
self.small_half = [] # 最大堆(负数模拟)
self.large_half = [] # 最小堆
# Min / Max 查询堆
self.min_heap = [] # 最小堆,用于 getMax
self.max_heap = [] # 最大堆(负数模拟),用于 getMin
# 懒删除标记
self.remove_set = defaultdict(int)
# 有效计数
self._count = 0
# 操作历史栈,用于 withdrawLatest
self._history: List[int] = []
def _clean_min_heap(self):
while self.min_heap and self.min_heap[0] in self.remove_set:
num = heapq.heappop(self.min_heap)
self.remove_set[num] -= 1
if self.remove_set[num] == 0:
del self.remove_set[num]
def _clean_max_heap(self):
while self.max_heap and -self.max_heap[0] in self.remove_set:
num = -heapq.heappop(self.max_heap)
self.remove_set[num] -= 1
if self.remove_set[num] == 0:
del self.remove_set[num]
def _clean_small(self):
while self.small_half and -self.small_half[0] in self.remove_set:
num = -heapq.heappop(self.small_half)
self.remove_set[num] -= 1
if self.remove_set[num] == 0:
del self.remove_set[num]
def _clean_large(self):
while self.large_half and self.large_half[0] in self.remove_set:
num = heapq.heappop(self.large_half)
self.remove_set[num] -= 1
if self.remove_set[num] == 0:
del self.remove_set[num]
def addNum(self, num: int) -> None:
self._history.append(num)
self._count += 1
# 推入中位数双堆
heapq.heappush(self.small_half, -num)
moved = -heapq.heappop(self.small_half)
heapq.heappush(self.large_half, moved)
if len(self.small_half) < len(self.large_half):
moved_back = heapq.heappop(self.large_half)
heapq.heappush(self.small_half, -moved_back)
# 推入 min/max 堆
heapq.heappush(self.min_heap, num)
heapq.heappush(self.max_heap, -num)
def getMax(self) -> Optional[int]:
self._clean_min_heap() # min_heap 存最小值,最大值用 max_heap
self._clean_max_heap()
if not self._count:
return None
return -self.max_heap[0]
def getMin(self) -> Optional[int]:
self._clean_min_heap()
self._clean_max_heap()
if not self._count:
return None
return self.min_heap[0]
def getMedian(self) -> Optional[float]:
self._clean_small()
self._clean_large()
if not self._count:
return None
if len(self.small_half) > len(self.large_half):
return float(-self.small_half[0])
elif len(self.large_half) > len(self.small_half):
return float(self.large_half[0])
else:
return (-self.small_half[0] + self.large_half[0]) / 2.0
def withdrawLatest(self) -> Optional[int]:
"""撤回最近一次添加的数"""
if not self._history:
return None
num = self._history.pop()
self._count -= 1
# 懒删除标记:所有堆在下次清理时自动跳过
self.remove_set[num] += 1
return num设计亮点
- 高内聚:中位数逻辑、极值逻辑、撤回逻辑各自独立封装,互不侵入
- 可复用:双堆中位数结构作为核心组件,可独立提取为
MedianFinder类 - 懒删除统一:所有删除(含
withdrawLatest)均走remove_set懒删除通道,避免多堆同步难题 - 撤回 O(1) 标记:
_history栈记录操作顺序,撤回时直接取栈顶,标记删除即可
复杂度总结
| 操作 | 时间复杂度 | 空间复杂度 |
|---|---|---|
addNum |
O(log n) | O(1) 额外 |
getMax |
O(log n) 均摊 | — |
getMin |
O(log n) 均摊 | — |
getMedian |
O(log n) 均摊 | — |
withdrawLatest |
O(1) | O(1) 额外 |
整体空间: O(n) — 每元素在多个堆中各存一份
第三轮:行为面试 (Behavioral Round)
第三轮由 Recruiter 主导,重点考察候选人的软实力与团队协作能力。
核心方法论:STAR 法则
- S (Situation):描述背景和场景
- T (Task):明确你面临的任务或挑战
- A (Action):详细说明你采取了哪些具体行动
- R (Result):展示结果和影响,最好量化
高频问题方向
- 冲突处理:与团队成员或上级发生分歧时如何协调?
- 失败经历:描述一次项目失败,你学到了什么?
- 影响力:如何在没有直接管理权的情况下推动项目进展?
- 价值观匹配:为什么选择 LinkedIn?你对平台的理解是什么?
准备建议
- 提前准备 4-6 个核心故事,覆盖技术挑战、团队冲突、领导力和失败复盘
- 每个故事都要有可量化的结果(如"将接口延迟降低 40%"而非"性能提升了")
- 避免空洞叙述,STAR 框架确保回答结构清晰、信息密度高
总结:面试核心能力要求
- 算法基础扎实:双堆法是经典高频考点,面试官会通过 Follow-up 层层深入考察扩展能力
- 系统设计思维:OOD 设计不仅要求功能正确,更要求代码结构的高内聚、低耦合、可复用
- 行为素养:清晰的沟通能力和成熟的团队协作意识是最终录用的关键因素
如果你正在准备 LinkedIn 或其他大厂的技术面试,需要更有针对性的模拟面试和代码辅导,欢迎通过 https://interview-help.live/contact 联系我们获取更多支持。