DocuSign VO 面试代面 2026 | 真实面经:Top K + Union Find + Topological Sort
📌 本文基于 2026 年真实 DocuSign 面试面经整理。深度解析电面与 VO 环节三道高频题目,附完整代码与解题框架。
📍 面经背景
- 公司: DocuSign
- 职位: SDE
- 地点: 西雅图
- RTO 政策: 每周一天
- 面试环节: 电面(1 轮)→ VO(3 轮)
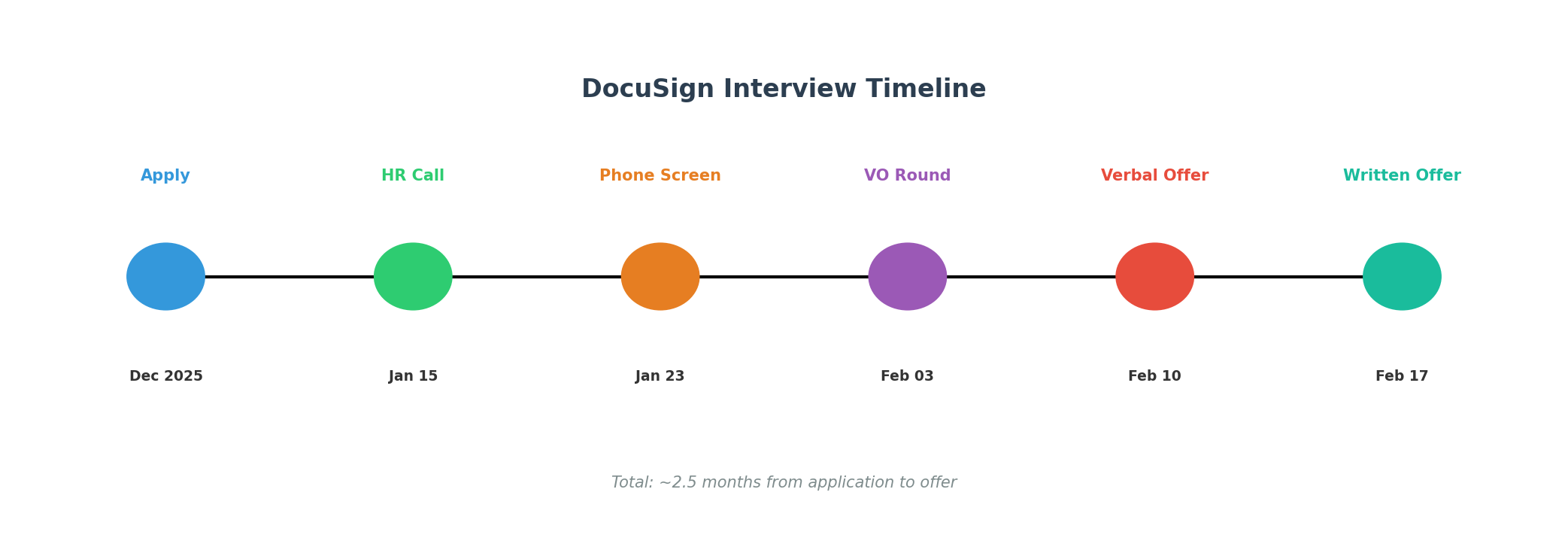
时间线
| 日期 | 阶段 |
|---|---|
| 2025-12-01 | 投递 |
| 2025-12-17 | HR Call(后失联) |
| 2026-01-05 | HR 重新联系 |
| 2026-01-15 | HR Call |
| 2026-01-23 | 电面 |
| 2026-01-26 | 电面通过,约 VO |
| 2026-02-03 | VO(3 轮) |
| 2026-02-10 | 口头 Offer |
| 2026-02-17 | 正式 Offer |
💡 备考提示:DocuSign 从投递到 Offer 整体周期约 2.5 个月,中间可能出现 HR 失联的情况,建议保持耐心并主动跟进。
🧠 电面:Course Schedule 变体(Topological Sort)
题目描述
面试官是三哥,先聊了工作经历和项目经验,剩余约 30 分钟做题。
给定一堆云资源(cloud resources)及其依赖关系,求初始化顺序。本质上是 课程表(Course Schedule) 问题的变体,核心是 拓扑排序(Topological Sort)。
示例输入:
resources = ["A", "B", "C", "D"]
dependencies = [("B", "A"), ("C", "A"), ("D", "B")]
# 表示:B 依赖 A,C 依赖 A,D 依赖 B示例输出:
["A", "B", "D", "C"] # 或 ["A", "C", "B", "D"] 均合法解题思路
方法 1:Kahn's Algorithm(BFS)— 推荐
- 时间复杂度: O(V + E)
- 空间复杂度: O(V + E)
- 优势:天然检测环路,且可以直接输出「无合法顺序」
from collections import defaultdict, deque
def topological_sort(resources, dependencies):
"""
给定资源列表和依赖关系,返回合法的初始化顺序。
若存在循环依赖则返回空列表。
"""
# 构建邻接表和入度表
graph = defaultdict(list)
in_degree = {r: 0 for r in resources}
for dependent, prerequisite in dependencies:
graph[prerequisite].append(dependent)
in_degree[dependent] += 1
# 初始化队列:入度为 0 的节点
queue = deque([r for r in resources if in_degree[r] == 0])
result = []
while queue:
node = queue.popleft()
result.append(node)
for neighbor in graph[node]:
in_degree[neighbor] -= 1
if in_degree[neighbor] == 0:
queue.append(neighbor)
# 如果结果长度等于资源总数,说明无环
return result if len(result) == len(resources) else []
# 示例
print(topological_sort(
["A", "B", "C", "D"],
[("B", "A"), ("C", "A"), ("D", "B")]
))
# 输出: ['A', 'B', 'D', 'C']方法 2:DFS + 三色标记
- 时间复杂度: O(V + E)
- 空间复杂度: O(V)
- 优势:无需额外队列,适合内存受限场景
from collections import defaultdict
def topological_sort_dfs(resources, dependencies):
"""DFS 版拓扑排序"""
graph = defaultdict(list)
WHITE, GRAY, BLACK = 0, 1, 2
color = {r: WHITE for r in resources}
result = []
for dependent, prerequisite in dependencies:
graph[prerequisite].append(dependent)
def dfs(node):
color[node] = GRAY
for neighbor in graph[node]:
if color[neighbor] == GRAY:
return False # 检测到环
if color[neighbor] == WHITE and not dfs(neighbor):
return False
color[node] = BLACK
result.append(node)
return True
for r in resources:
if color[r] == WHITE:
if not dfs(r):
return []
return result[::-1] # 逆序输出常见变体
| 变体 | 变化点 | 处理方式 |
|---|---|---|
| 检测环路 | 判断是否有合法顺序 | Kahn 算法结果长度比较 / DFS 三色标记 |
| 任意合法顺序 | 不要求唯一 | 任意 BFS/DFS 拓扑排序 |
| 字典序最小 | 要求字典序最小 | BFS 改用最小堆(min-heap) |
| 最少资源数 | 求最少课程数 | Kahn 算法直接计数 |
🧮 VO Round 1: Top K — 用户岗位筛选系统
题目描述
面试官是三姐,非常友好,热情介绍了团队情况,剩余约 35 分钟做题。
设计一个系统,实现以下三个函数:
createUser(userName, role)— 创建用户postJob(jobId, role, salary)— 发布岗位getTopKJobsByUser(userName, k)— 给指定用户筛选工资最高的 K 个岗位
关键约束:只有角色的匹配关系。用户有 role,岗位有 role,用户只能看到与其角色匹配的岗位。
解题思路
核心思想:维护用户 → 岗位的索引 + 最大堆(Min-Heap)求 Top K。
import heapq
from collections import defaultdict, OrderedDict
class JobSystem:
"""
用户岗位筛选系统
- 用户按角色创建
- 岗位按角色发布
- 用户可以查询自己角色匹配的工资最高的 K 个岗位
"""
def __init__(self):
# 用户表: userName -> role
self.users = {}
# 岗位表: jobId -> {role, salary}
self.jobs = {}
# 索引: role -> [(salary, jobId)] 用于快速查询
self.role_jobs = defaultdict(list)
def create_user(self, user_name: str, role: str):
"""创建用户"""
self.users[user_name] = role
def post_job(self, job_id: str, role: str, salary: float):
"""发布岗位"""
self.jobs[job_id] = {"role": role, "salary": salary}
self.role_jobs[role].append((salary, job_id))
def get_top_k_jobs(self, user_name: str, k: int) -> list:
"""
给指定用户返回工资最高的 K 个匹配岗位
使用 min-heap 维护 top-k,O(N log K)
"""
if user_name not in self.users:
return []
role = self.users[user_name]
candidates = self.role_jobs.get(role, [])
# 使用 min-heap 维护 top-k 个元素
# 堆中始终保存工资最高的 k 个
heap = []
for salary, job_id in candidates:
if len(heap) < k:
heapq.heappush(heap, (salary, job_id))
elif salary > heap[0][0]:
heapq.heapreplace(heap, (salary, job_id))
# 按工资降序返回
result = [(jid, sal) for sal, jid in heap]
result.sort(key=lambda x: -x[1])
return result
# 示例
system = JobSystem()
system.create_user("Alice", "ENGINEER")
system.create_user("Bob", "MANAGER")
system.post_job("J1", "ENGINEER", 150000)
system.post_job("J2", "ENGINEER", 200000)
system.post_job("J3", "ENGINEER", 120000)
system.post_job("J4", "MANAGER", 180000)
system.post_job("J5", "ENGINEER", 170000)
print(system.get_top_k_jobs("Alice", 2))
# [('J2', 200000), ('J5', 170000)]
print(system.get_top_k_jobs("Bob", 2))
# [('J4', 180000)]复杂度分析
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
create_user |
O(1) | 哈希表插入 |
post_job |
O(1) | 哈希表插入 |
get_top_k_jobs |
O(N log K) | N = 该角色岗位数,堆维护 K 个元素 |
Follow-up: 如果数据量极大?
- Bloom Filter + 分桶排序:按工资范围分桶,从最高桶开始取
- QuickSelect:O(N) 平均找到第 K 大的工资阈值
- 数据库方案:
SELECT * FROM jobs WHERE role = ? ORDER BY salary DESC LIMIT K

🧮 VO Round 2: Union Find — 账户邮箱合并
题目描述
面试官是三哥,比较严肃,没有太多闲聊,直接开始做题。时间比较紧张。
给定用户名和多个邮箱的对应关系,有相同邮箱的视为同一个人,需要合并同一个人的所有邮箱。
示例输入:
accounts = [
["John", "john@example.com", "john.doe@gmail.com"],
["John", "john.doe@gmail.com", "john@company.com"],
["Jane", "jane@example.com"],
["John", "john@company.com", "j.doe@other.com"]
]示例输出:
[
["John", "j.doe@other.com", "john.doe@gmail.com", "john@example.com", "john@company.com"],
["Jane", "jane@example.com"]
]解题思路
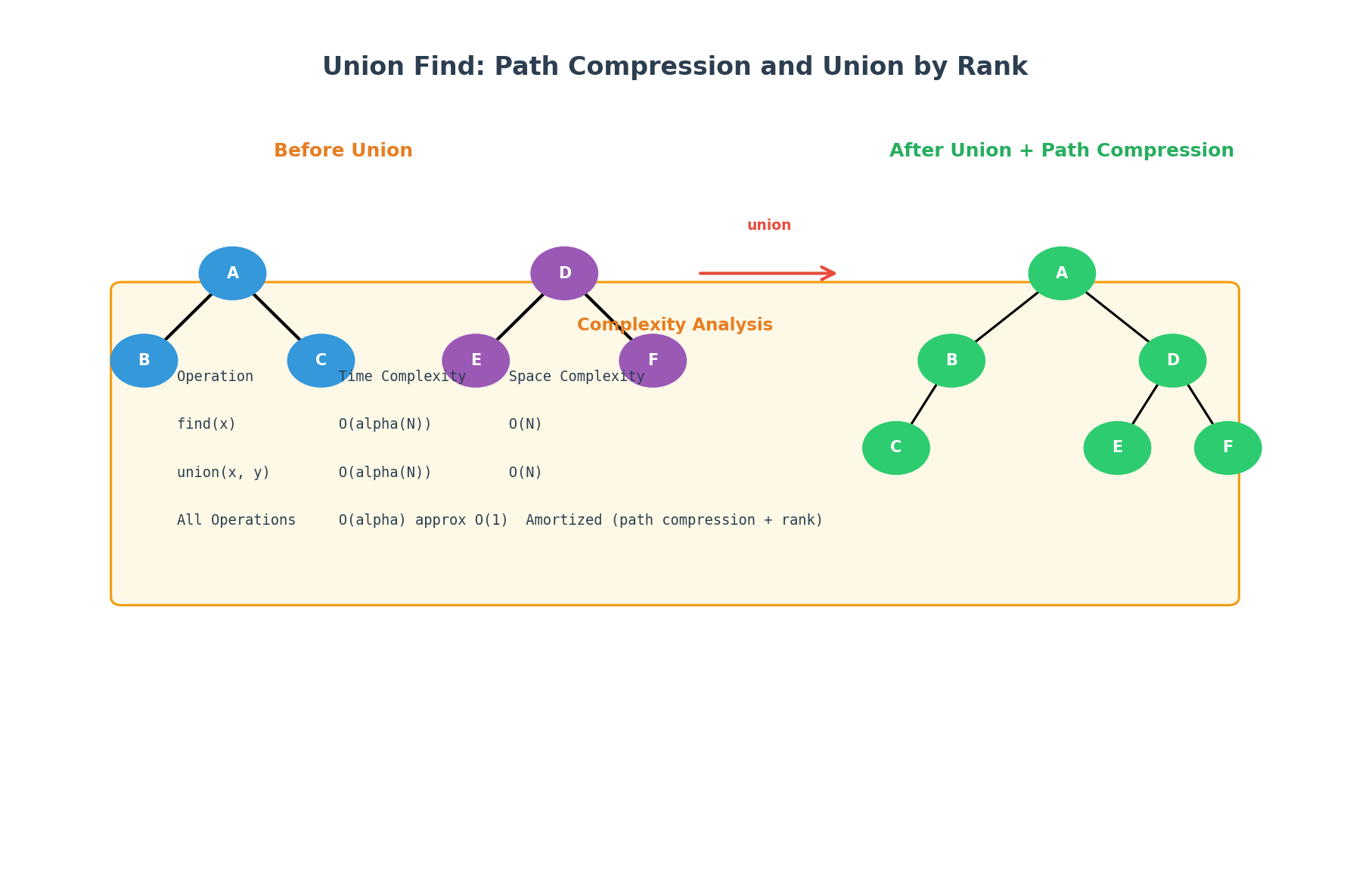
核心思想:Union-Find(并查集)。每个邮箱是一个节点,如果两个邮箱出现在同一个账户列表中,则将它们合并。
class UnionFind:
"""并查集"""
def __init__(self):
self.parent = {}
self.rank = {}
def find(self, x):
"""路径压缩"""
if self.parent[x] != x:
self.parent[x] = self.find(self.parent[x])
return self.parent[x]
def union(self, x, y):
"""按秩合并"""
rx, ry = self.find(x), self.find(y)
if rx == ry:
return False
if self.rank[rx] < self.rank[ry]:
rx, ry = ry, rx
self.parent[ry] = rx
if self.rank[rx] == self.rank[ry]:
self.rank[rx] += 1
return True
def connected(self, x, y):
return self.find(x) == self.find(y)
def account_merge(accounts: list) -> list:
"""
合并所有关联账户
"""
uf = UnionFind()
email_to_name = {}
# 第一步:将同一账户中的邮箱合并
for account in accounts:
name = account[0]
for email in account[1:]:
email_to_name[email] = name
if email != account[1]:
uf.union(email, account[1])
# 确保每个邮箱都加入并查集
if email not in uf.parent:
uf.parent[email] = email
uf.rank[email] = 0
# 第二步:按根节点分组
root_to_emails = defaultdict(list)
for email in email_to_name:
root = uf.find(email)
root_to_emails[root].append(email)
# 第三步:组装结果
result = []
for root, emails in root_to_emails.items():
name = email_to_name[root]
emails.sort()
result.append([name] + emails)
return result
# 示例
accounts = [
["John", "john@example.com", "john.doe@gmail.com"],
["John", "john.doe@gmail.com", "john@company.com"],
["Jane", "jane@example.com"],
["John", "john@company.com", "j.doe@other.com"]
]
print(account_merge(accounts))
# [['John', 'j.doe@other.com', 'john.doe@gmail.com', 'john@example.com', 'john@company.com'],
# ['Jane', 'jane@example.com']]复杂度分析
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
find |
O(α(N)) | 路径压缩 + 按秩合并,α 为反阿克曼函数(≈ 常数) |
union |
O(α(N)) | 同上 |
| 整体合并 | O(N log N) | 主要是排序步骤 |
Follow-up: Union Find 常见面试考点
| 考点 | 实现方式 |
|---|---|
| 路径压缩 | find 中递归将节点直接指向根 |
| 按秩合并 | 始终将矮树挂在高树下 |
| 按大小合并 | 将小树挂到大树下,维护 size |
| 连通分量计数 | 每次 union 成功则 count -= 1 |
| 动态图 | 支持加边查询连通性 |
🎯 VO Round 3: Behavioral Questions + JSON Design
面试官背景
面试官比较友好,先聊了常规 BQ 和项目经验,最后让设计一个面向用户的 JSON 结构,难度不高。
BQ 推荐回答框架
DocuSign 作为企业 SaaS 公司,BQ 通常关注以下维度:
- 客户导向(Customer Focus):如何理解用户需求并交付价值
- 跨团队协作(Collaboration):如何与 PM、Design、后端协作
- 解决问题(Problem Solving):遇到技术难题时的分析过程
- 成长思维(Growth Mindset):如何从失败中学习
推荐故事准备
| 场景 | STAR 框架 | 关键指标 |
|---|---|---|
| 技术攻坚 | S: 复杂 bug / T: 排查修复 / A: 根因分析 + 修复 / R: 性能提升 X% | 量化性能改善 |
| 跨团队协作 | S: 需求冲突 / T: 达成一致 / A: 主动沟通 + 折中方案 / R: 按时交付 | 交付时间 |
| 用户反馈 | S: 用户投诉 / T: 优化体验 / A: 数据分析 + 方案迭代 / R: NPS 提升 | NPS/满意度 |
JSON Design 部分
面试官要求设计一个面向用户的 JSON 结构。这类问题的核心要点:
- 语义清晰:字段名有明确含义
- 可扩展性:预留扩展字段
- 版本兼容:支持多版本
- 用户可读:避免过度嵌套
{
"version": "1.0",
"document": {
"id": "doc_12345",
"title": "Service Agreement",
"status": "pending_signature",
"created_at": "2026-02-01T00:00:00Z",
"recipients": [
{
"name": "John Doe",
"email": "john@example.com",
"role": "signer",
"tabs": [
{
"type": "signature",
"page": 1,
"x": 100,
"y": 200
}
]
}
]
}
}💡 面试经验总结
- 电面准备:电面约 30 分钟做题,拓扑排序是图论经典题目,务必掌握 Kahn 和 DFS 两种写法
- VO 时间管理:Round 2 反馈时间紧张,建议每题前 5 分钟确认题意,避免理解偏差浪费���间
- Top K 问题:注意角色匹配这一约束条件,不要简单全局排序
- Union Find:面试中手写并查集时,路径压缩和按秩合并是加分项
- HR 跟进:DocuSign HR 可能出现失联情况(面经中 HR 消失 2 周),建议主动发邮件跟进
📞 需要 DocuSign 面试辅导?
如果你正在准备 DocuSign 面试,我们可以帮你:
- ✅ 电面辅导:Topological Sort、Graph 等高频题目精讲
- ✅ VO 代面:Top K、Union Find 等核心算法深度解析
- ✅ BQ 辅导:STAR 框架 + 定制个人故事
- ✅ 全流程服务:从电面到 VO 每个环节都帮你搞定
📌 本文基于 2026 年真实 DocuSign 面试面经整理。更多面经持续更新中…