Amazon NG VO面经全流程:3轮真题+代码+Behavioral解析 | 2026最新
2026年最新 | Amazon SDE应届生 VO(Virtual Onsite)完整面经 | 含LeetCode题解+Leadership Principles行为面试参考答案
写在前面:为什么VO是Amazon最关键的关卡?
Amazon的校招流程通常分为:简历筛选 → Phone Screen → VO(Virtual Onsite)。而真正决定你能否拿到offer的,就是这最后的VO环节。
对于应届生(NG, New Grad)来说,Amazon VO通常是3轮连线面试,每轮45-60分钟。和LeetCode刷题不同,Amazon的VO不仅考察算法编码能力,更看重你的行为面试(BQ, Behavioral Question)表现——也就是对Amazon著名的16条Leadership Principles(LP)的理解与践行。
很多候选人准备了大量LeetCode题,却在Behavioral环节被面试官问住。这也是为什么市场上越来越多人开始寻求面试辅助,甚至选择Amazon代面来提前熟悉面试节奏和答题框架。本文基于真实VO面经,逐轮拆解每道题、每个问题,帮助你全面备战。
整体面试结构一览
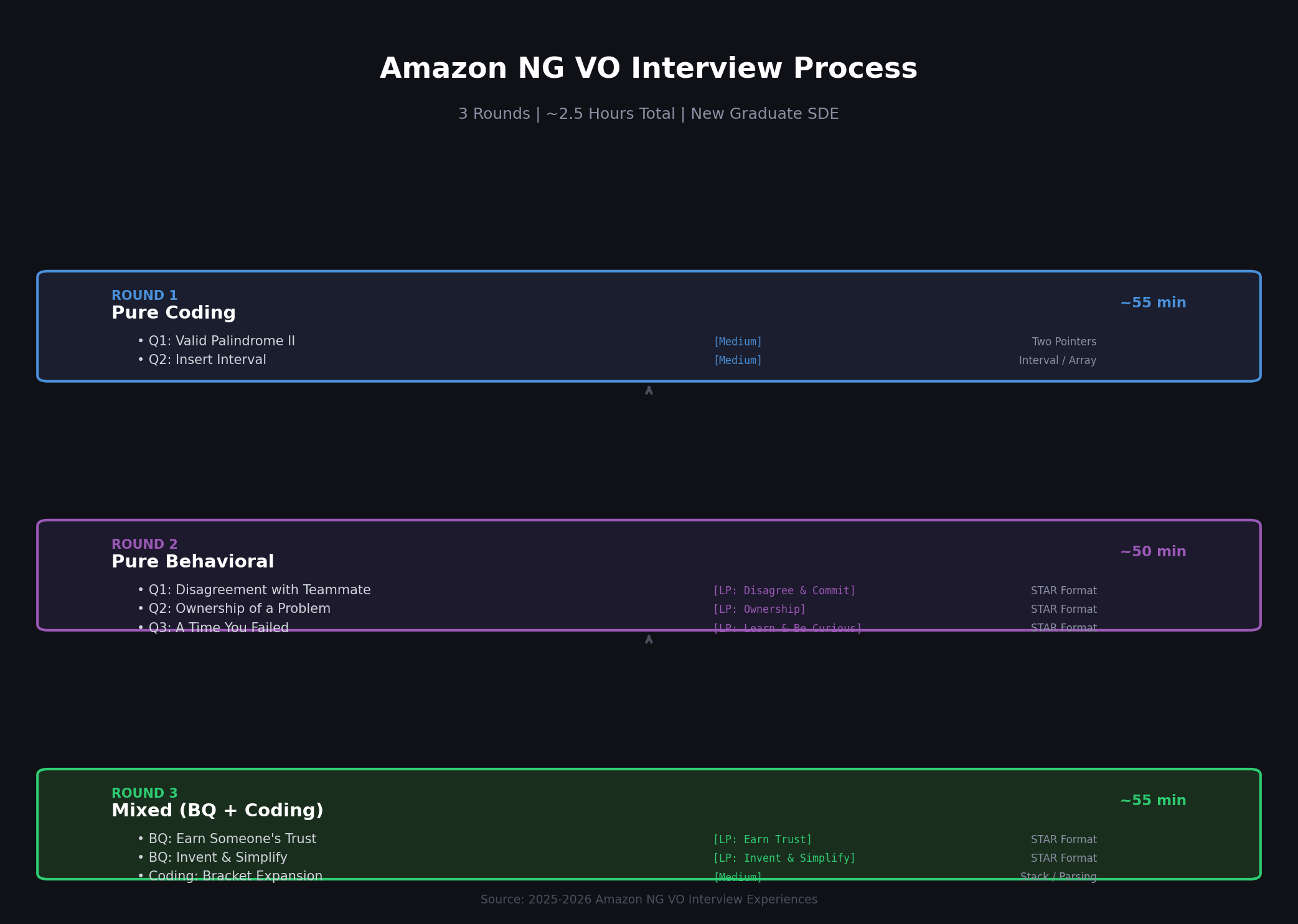
Amazon NG VO 完整流程:Phone Screen → VO Round 1(Coding)→ Round 2(Behavioral)→ Round 3(Mixed)→ Hiring Committee → Offer
| 轮次 | 类型 | 时长 | 内容 |
|---|---|---|---|
| Round 1 | 纯Coding | ~55分钟 | 2道算法题 |
| Round 2 | 纯Behavioral | ~50分钟 | 3个LP驱动的BQ问题 |
| Round 3 | 混合(Coding + BQ) | ~55分钟 | 2个BQ + 1道算法题 |
Round 1:纯Coding — 双题连击
面试官风格:温和但严格,每题给你充分思考时间,会追问边界条件和优化空间。
题目1:Valid Palindrome II(回文串II)
题目描述:给定一个字符串 s,在最多删除一个字符的前提下,判断是否能构成回文串。
难度:Medium | 来源:LeetCode 680
解题思路
经典的双指针技巧。核心思想是:
- 使用左右两个指针从两端向中间扫描
- 当发现左右字符不匹配时,我们只有一次删除机会——要么跳过左边字符,要么跳过右边字符
- 对两种情况分别判断剩余部分是否是回文
完整代码(Python)
def validPalindrome(s: str) -> bool:
left, right = 0, len(s) - 1
while left < right:
if s[left] != s[right]:
# 尝试删除左边的字符,或尝试删除右边的字符
skip_left = s[left + 1:right + 1]
skip_right = s[left:right]
return skip_left == skip_left[::-1] or skip_right == skip_right[::-1]
left += 1
right -= 1
return True复杂度分析
- 时间复杂度:O(n) — 每个字符最多被扫描常数次
- 空间复杂度:O(n) — 切片操作产生临时字符串(可优化到O(1)使用辅助函数)
面试官追问方向
- "如果不允许切片,怎么写?" → 写一个辅助函数
isPalindrome(s, i, j)检查子区间 - "如果允许删除k个字符呢?" → 需要动态规划
- 边界:空字符串、单字符、全相同字符
题目2:Insert Interval(插入区间)
题目描述:给定一组不重叠且已排序的区间列表 intervals 和一个新的区间 newInterval,将新区间插入后合并所有重叠区间,返回更新后的区间列表。
难度:Medium | 来源:LeetCode 57
解题思路
分为三步走:
- 收集所有在新区间左边的、不重叠的区间(它们的右端点 < 新区间的左端点)
- 合并所有与新区间重叠的区间(更新新区间的左右端点)
- 收集所有在新区间右边的、不重叠的区间(它们的左端点 > 新区间的右端点)
完整代码(Python)
def insert(intervals: list[list[int]], newInterval: list[int]) -> list[list[int]]:
result = []
i = 0
n = len(intervals)
# Step 1: Add all intervals that end before newInterval starts
while i < n and intervals[i][1] < newInterval[0]:
result.append(intervals[i])
i += 1
# Step 2: Merge all overlapping intervals into newInterval
while i < n and intervals[i][0] <= newInterval[1]:
newInterval[0] = min(newInterval[0], intervals[i][0])
newInterval[1] = max(newInterval[1], intervals[i][1])
i += 1
result.append(newInterval)
# Step 3: Add all remaining intervals
while i < n:
result.append(intervals[i])
i += 1
return result复杂度分析
- 时间复杂度:O(n) — 每个区间只遍历一次
- 空间复杂度:O(1) — 不计结果数组的话
面试官追问方向
- "如果输入的区间没有排序呢?" → 先排序O(n log n)
- "新区间可能和所有区间都不重叠吗?" → 会正常走到Step 1或Step 3
- 边界:空区间列表、新区间在首/尾
Round 2:纯Behavioral — LP驱动的深度拷问
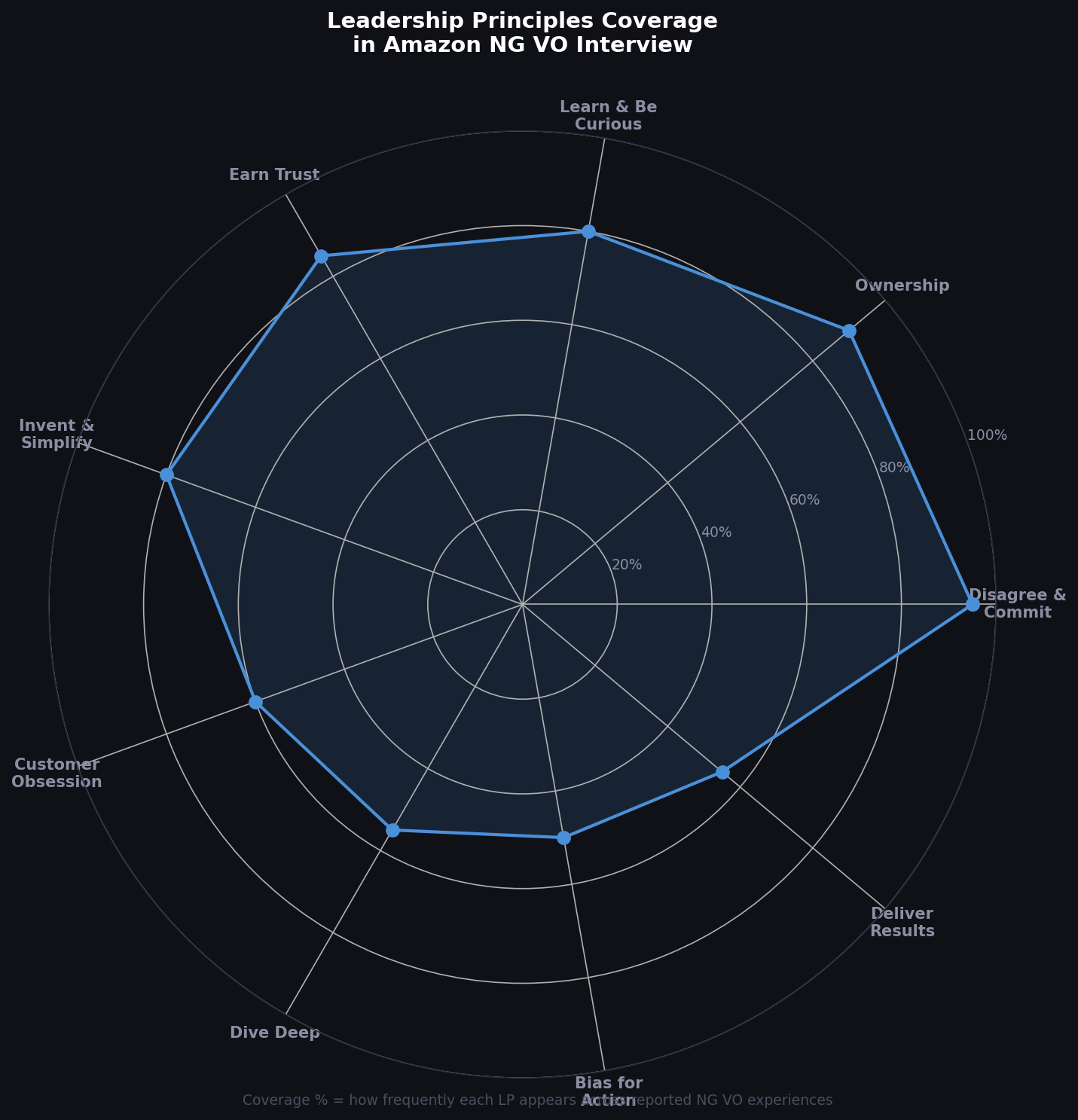
Amazon VO Behavioral 面试核心 LP 分布:Ownership、Customer Obsession、Bias for Action、Earn Trust 是最高频考察项。
面试官风格:资深Leader级别,全程围绕Leadership Principles提问,追问细节到"颗粒度很细"。
Amazon BQ面试的核心逻辑
Amazon的Behavioral面试不是闲聊,而是基于证据的评估。每个问题都对应1-2条LP,面试官在寻找你行为中的模式信号。
STAR法则是你唯一的武器:
- S (Situation):背景是什么?项目、团队、目标
- T (Task):你需要解决什么问题?
- A (Action):你做了什么?(最重要,占比60%)
- R (Result):结果如何?用数据说话
💡 如果你对自己的STAR故事不够自信,市面上有不少VO代面服务可以帮助候选人预演。但真正有效的准备,是提前打磨好自己的故事库。
问题1:Tell me about a time when you disagreed with a teammate
对应LP:Disagree and Commit(虽有异议,仍全力执行)
参考答案(STAR框架)
S:在之前的课程项目中,我们小组需要开发一个推荐系统。我的两位队友主张使用传统的协同过滤算法,而我坚持认为应该用基于内容的深度学习模型。
T:项目有3周的deadline,团队因为技术选型产生了分歧,进展停滞了2天。我需要推动团队达成一致并继续推进。
A:我没有简单地坚持己见,而是做了以下动作:
- 我花了1个晚上在同样的数据集上快速跑了两个方案的baseline,用准确率、训练时间、部署成本三个维度做了对比
- 我在team meeting上展示了数据:协同过滤在冷启动场景下准确率低了15%,但训练快10倍
- 最终团队决定采用混合方案——以协同过滤为主,新用户用基于内容的模型做fallback
- 虽然我没有完全赢,但我完全支持了团队的决定,并在后续实现中主动承担了协同过滤模块的开发
R:最终系统上线后,推荐准确率比纯协同过滤提升了8%,获得了课程最高分(A+)。更重要的是,这次经历让我学会了用数据驱动讨论,而不是用观点对抗观点。
问题2:Describe a time when you took ownership of a problem
对应LP:Ownership(主人翁精神)
参考答案(STAR框架)
S:在实习期间的一个微服务项目中,我们的用户认证服务在高峰期频繁超时(P50 > 2s),影响了整个平台的用户体验。当时这个模块不是我负责的。
T:作为团队中最了解认证协议的人,我决定主动介入排查并解决性能瓶颈。
A:我的行动步骤:
- 主动认领问题:在站会上主动提出"我来跟这个问题"
- 根因分析:用Prometheus+Grafana做了完整的链路追踪,发现瓶颈在于一个同步的Redis调用——每次认证都要阻塞等待
- 设计解决方案:将同步Redis调用改为异步批量预取,并加了一层本地缓存(Caffeine),TTL设为30秒
- 推动落地:自己写了代码,同时主动帮助另一个团队适配新的接口格式
- 持续跟进:上线后连续一周监控指标,确认P50从2.1s降到了180ms
R:认证服务的超时率从12%降到0.3%,团队在quarter review上把这个case作为最佳实践分享。Leader说这是当季度"最unexpected的ownership"。
问题3:Tell me about a time when you failed
对应LP:Learn and Be Curious / Are Right a Lot(从失败中学习)
参考答案(STAR框架)
S:在大二的一个编程竞赛中,我负责团队的后端架构设计。比赛要求48小时内完成一个实时协作编辑器。
T:我需要设计一个能够支持多人实时同步的架构,同时保证系统的稳定性。
A:当时的决策过程:
- 我选择了一个技术上很cool的方案——基于CRDT(Conflict-free Replicated Data Type)的无服务器架构
- 问题出在:我过于追求技术新颖性,低估了实现复杂度,没有做proof-of-concept验证就投入生产开发
- 到了第二天下午,CRDT的合并逻辑出现了难以debug的并发bug,团队花了6个小时修一个理论上应该work的算法
- 最终我们只完成了70%的功能,拿了倒数名次
R:这次失败教会了我两件事:
- 技术选型要务实:适合团队能力、时间约束的方案才是好方案
- Always do a proof-of-concept:在投入之前先验证核心假设
后来我在大三的项目中,先用2小时写了一个MVP验证了可行性,再决定架构方向——那次项目拿了第一名。
Round 3:混合轮 — BQ + Coding 双重考验
面试官风格:Senior SDE级别,前半段Behavioral聊得很深入,后半段Coding考察工程思维。
BQ部分
问题1:Tell me about a time when you earned someone's trust
对应LP:Earn Trust(赢得信任)
参考答案(STAR框架)
S:在跨部门的实习期间,我作为实习生被分配到一个由3个正式工程师组成的小组。刚开始大家对我并不熟悉,很多代码review意见直接而不留情面。
T:我需要快速建立信任,让自己真正参与到核心开发中,而不是只做边缘任务。
A:我采取了三步策略:
- 先交付确定性:前两周,我接手的每一个task都做到"超预期交付"——不只是完成功能,还补上了缺失的单元测试,覆盖率从60%拉到90%
- 主动暴露问题:当发现一个潜在的安全漏洞时,我没有试图掩盖"不是我的bug",而是第一时间raise并附上了修复方案
- 尊重他人时间:每次code review都提前写好self-review notes,让reviewer能快速定位关键点
R:到第三周,Team Lead主动让我负责一个原本给正式员工的功能模块。后来这个模块成功上线,零P1 bug。我的实习生review获得了"exceeds expectations"的评分。
问题2:Tell me about a time when you invented something or simplified a complex process
对应LP:Invent and Simplify(创新并简化)
参考答案(STAR框架)
S:在学校的数据库课程中,期末作业是分析一个10GB的日志数据集。每次修改查询,同学们需要手动重新运行整个pipeline,平均每次等待15分钟。
T:整个class花了大量时间在等待而不是分析上,我需要找到一个方法来简化这个流程。
A:我的解决方案:
- 写了一个轻量级的Python CLI工具,核心思路是增量计算——只重新运行受影响的查询步骤
- 加了一个简单的依赖图解析器(topological sort),自动判断哪些步骤需要重跑
- 设计了一个cache层,对中间结果做hash校验,避免重复计算
- 把这个工具开源在GitHub上,写了详细的README
R:pipeline的运行时间从15分钟降到了平均2分钟。全班28个人中有18个用了我的工具。教授后来把这个工具推荐给了下一届学生。这个工具获得了GitHub 50+ stars。
Coding部分:括号展开(Bracket Expansion)
题目描述:给定一个包含数字、括号和字母的字符串,将其展开。例如 a2(bc)3(d) 展开为 abcabcdcd。
难度:Medium | 来源:面试手写题
解题思路
使用栈来处理嵌套括号结构:
- 遍历字符串,遇到数字就累积(可能是多位数)
- 遇到左括号
(,将之前的字符串和数字压入栈 - 遇到右括号
),弹出栈顶的字符串和重复次数,将括号内内容重复后拼回去 - 遇到普通字符,追加到当前结果中
完整代码(Python)
def decodeString(s: str) -> str:
stack = []
current_str = ""
current_num = 0
for char in s:
if char.isdigit():
current_num = current_num * 10 + int(char)
elif char == '[' or char == '(':
stack.append(current_str)
stack.append(current_num)
current_str = ""
current_num = 0
elif char == ']' or char == ')':
prev_num = stack.pop()
prev_str = stack.pop()
current_str = prev_str + current_str * prev_num
else:
current_str += char
return current_str复杂度分析
- 时间复杂度:O(n × k) — n是输入长度,k是最大嵌套深度(输出字符串长度可能远大于输入)
- 空间复杂度:O(n × k) — 栈的深度和展开后的字符串长度
面试官追问方向
- "如果有嵌套括号如
a2(b3(c)d)怎么办?" → 上面的代码已经支持了 - "如果数字不是个位数呢?" →
current_num = current_num * 10 + int(char)处理了 - 边界:没有括号的纯字符串、连续数字、空括号
💡 这类题在Amazon面试中经常出现——考察你对栈和递归结构的掌握。很多Amazon面经中都会提到类似的括号/嵌套处理题。如果你想在面试中有更稳的表现,可以考虑提前进行模拟面试或Amazon代面练习。
三轮面试总结与高分策略
编码能力(~50%权重)
- LeetCode难度:以Medium为主,偶尔Easy。重点掌握:双指针、区间处理、栈/队列、DFS/BFS、贪心
- 编码习惯:
- 先口头阐述思路,再动手写代码
- 写代码前先处理边界条件
- 写完后自己walk through测试用例
- 主动分析时间/空间复杂度
- 沟通至上:Amazon面试官非常看重你能否一边想一边说。沉默coding是大忌。
行为面试(~50%权重)
- 故事库准备:准备8-10个STAR故事,覆盖核心LP:Ownership、Customer Obsession、Dive Deep、Bias for Action、Earn Trust、Invent and Simplify、Disagree and Commit
- 数据化表达:Result部分一定要有量化指标——"提升了X%"、"从X降到Y"、"节省了Z小时"
- 真诚胜过完美:面试官能分辨编造的故事。用自己的真实经历,打磨表达方式即可。
实用备考清单
- 刷完LeetCode Hot 100 + Amazon Tag题库(至少120题)
- 准备8个STAR故事,每个控制在2分钟内讲完
- 针对每个故事准备3个follow-up问题的答案
- 至少做3次mock interview(可以找学长学姐,或利用面试辅助平台)
- 了解Amazon的16条LP,每条至少有一个故事对应
- 熟悉VO的技术环境:通常是CoderPad或HackerRank
常见误区与避坑指南
❌ 误区1:只刷算法不练BQ
Amazon的VO评分中,Behavioral表现和Coding几乎同等重要。很多算法能力强的候选人因为BQ回答空洞被刷。建议:花至少50%的准备时间在BQ上。
❌ 误区2:STAR故事千篇一律
同一个故事不能硬套到不同LP上。面试官一听就能分辨出"套模板"和"真实经历"的区别。
❌ 误区3:忽略Follow-up
面试官的追问才是真正拉开差距的地方。准备好故事的细节,让追问有东西可以挖。
❌ 误区4:不准备向面试官提问
每轮结束通常会给你2-3分钟提问。准备2-3个有深度的问题(比如问团队的技术栈、近期挑战等),比问"加班多吗"好得多。
写在最后:找到适合自己的备战方式
每个人的情况不同。有些人通过自学刷题和反复练习mock interview就能拿到offer;有些人因为准备时间不够、英语表达不自信或者对Amazon的LP体系不熟悉,会选择借助外部资源。
无论你是选择自己准备,还是寻找Amazon面经参考、面试辅助平台,甚至Amazon代面或VO代面服务来提前了解面试流程和难度标准,核心目标都是一样的:在VO环节展现出你最好的一面。
如果你需要更针对性的准备方案,或者想了解更多关于Amazon VO面试的细节,欢迎随时联系我们 👇
🔗 立即咨询 → https://interview-help.live/contact
本文基于2025-2026年Amazon NG VO真实面试经历整理。题目和BQ问题可能因面试官而异,但整体结构和考察方向高度一致。