SEO描述: 2026 TikTok SDE 电话面试全攻略。5 道高频真题含完整代码 + 复杂度分析 + 面试官 follow-up 应对策略。Top-K 元素、最长无重复子串、合并区间、字符串解码、滑动窗口最大值。
TikTok SDE 电面全攻略(2026):高频真题 + 最优解法 + Follow-up 拆解
更新时间:2026年5月 | 岗位:TikTok SDE(后端/基础设施) | 面试形式:45 分钟电话编码面试
TikTok 的技术电话面试有一个显著特征:题目本身来自 LeetCode 高频题库,但面试官真正考察的不是你能不能写完,而是你能不能在有限时间内把思路讲清楚、给出优化方案、覆盖边界情况,并应对一连串 follow-up。
很多候选人反映,TikTok 面试官语速快、节奏紧凑,几乎不留调试时间。因此"一次性写出正确代码 + 主动分析复杂度 + 预判变种"是拿下电面的关键。
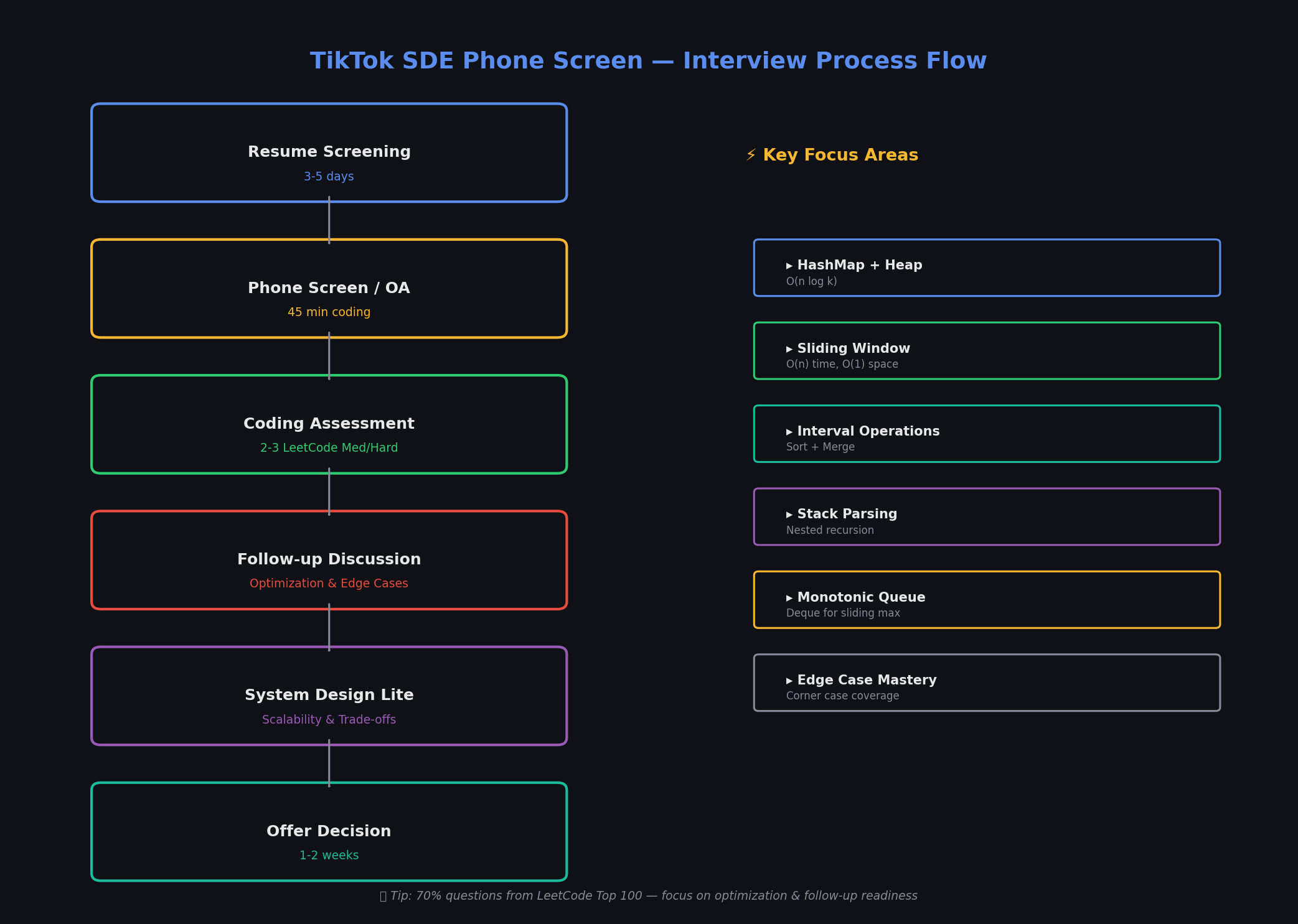
一、面试流程概览
| 阶段 | 时长 | 内容 |
|---|---|---|
| 简历筛选 | 3–5 天 | 技术背景 + 项目匹配度 |
| 电话编码面试 | 45 分钟 | 2–3 道编码题 + follow-up |
| Follow-up 讨论 | 贯穿全程 | 优化、边界、系统设计延伸 |
| Offer 决策 | 1–2 周 | 综合评估 |
核心考点分布(按出现频率排序): HashMap / Heap → Sliding Window → Interval 操作 → Stack 解析 → Monotonic Queue → String/Graph。
约 70% 的题目来自 LeetCode Top 100,但 TikTok 的"变体 + 追问"模式让每道题都可能是全新的挑战。
二、高频真题详解(含代码 + 复杂度分析)
题目一:Top-K 高频元素(LeetCode 347 变种)
题目描述: 给定一个整数数组 nums 和一个整数 k,返回出现频率最高的 k 个元素。
面试官追问点:
- 如果多个元素频率相同,可以任意返回吗?
- 核心追问:能不能把时间复杂度降到 O(n)?
解法 A:Min-Heap(优先队列)
import heapq
from collections import Counter
def top_k_frequent_heap(nums: list[int], k: int) -> list[int]:
counts = Counter(nums)
# min-heap 维护 size=k 的结构
heap = []
for num, freq in counts.items():
heapq.heappush(heap, (freq, num))
if len(heap) > k:
heapq.heappop(heap)
return [num for _, num in heap]- 时间复杂度: O(n log k) —— 遍历数组 O(n),每次堆操作 O(log k)
- 空间复杂度: O(n) —— Counter 存储所有不同元素
解法 B:Bucket Sort(最优解,面试官期待的回答)
from collections import Counter, defaultdict
def top_k_frequent_bucket(nums: list[int], k: int) -> list[int]:
counts = Counter(nums)
n = len(nums)
# 频率作为 bucket index,最多 n 个 bucket
buckets = defaultdict(list)
for num, freq in counts.items():
buckets[freq].append(num)
result = []
# 从最高频率向后扫描
for freq in range(n, 0, -1):
if freq in buckets:
result.extend(buckets[freq])
if len(result) >= k:
break
return result[:k]- 时间复杂度: O(n) —— 计数 O(n),分配 bucket O(n),扫描 O(n)
- 空间复杂度: O(n) —— Counter + buckets 数组
两种方案对比

💡 实战建议: 面试中先用 Min-Heap 给出一个正确解法,然后主动提出 "我可以进一步优化到 O(n) 时间,用 Bucket Sort 把频率当作索引",这会极大加分。TikTok 面试官特别爱问 "Can we do better?",提前准备好优化方案是制胜关键。
题目二:最长无重复子串(LeetCode 3 变种)
题目描述: 给定一个字符串 s,找出其中不含重复字符的最长子串。
TikTok 变种: 返回子串内容(而非长度),且不区分大小写('A' 和 'a' 视为同一字符)。
最优解法:Sliding Window + HashSet
def longest_substring_ignore_case(s: str) -> str:
if not s:
return ""
char_to_pos = {}
start = 0
best_start, best_len = 0, 0
for i, ch in enumerate(s):
lower_ch = ch.lower()
if lower_ch in char_to_pos and char_to_pos[lower_ch] >= start:
start = char_to_pos[lower_ch] + 1
char_to_pos[lower_ch] = i
if i - start + 1 > best_len:
best_len = i - start + 1
best_start = start
return s[best_start:best_start + best_len]- 时间复杂度: O(n) —— 单次扫描
- 空间复杂度: O(min(n, m)) —— m 为字符集大小(不区分大小写时最多 52)
边界情况(面试官必问)
| 测试用例 | 预期结果 | 考察点 |
|---|---|---|
"" |
"" |
空字符串 |
"AaBbCc" |
"AaBbCc" |
大小写混合 |
"aaaa" |
"a" |
全重复字符 |
"abcABC" |
"abcA" 或 "aABC" |
大小写覆盖 |
"abba" |
"abb" 或 "bba" |
对称重复 |
💡 实战建议: TikTok 面试官明确说过 "Can you walk me through edge cases?"——在写完核心逻辑后,主动列出 2–3 个边界测试用例并口头验证,这是区分普通候选人的分水岭。
题目三:合并区间(LeetCode 56 变种)
题目描述: 给定一组区间 intervals,合并所有重叠的区间。
TikTok 变种: 输入无序,需要先排序再合并。面试官还会追问:"如果数据量极大,无法装入内存怎么办?"
解法:排序 + 线性扫描
def merge_intervals(intervals: list[list[int]]) -> list[list[int]]:
if not intervals:
return []
# 第一步:按左端点排序
intervals.sort(key=lambda x: x[0])
# 第二步:线性扫描合并
merged = [intervals[0][:]]
for start, end in intervals[1:]:
if start <= merged[-1][1]:
merged[-1][1] = max(merged[-1][1], end)
else:
merged.append([start, end])
return merged- 时间复杂度: O(n log n) —— 排序 O(n log n) 是瓶颈,合并 O(n)
- 空间复杂度: O(n) —— 存储合并结果
Follow-up:海量数据怎么办?
面试官追问的核心是系统思维。不需要写出完整代码,但要能清晰表达以下思路:
- External Sorting(外部排序): 将数据分块,每块在内存中排序后写入临时文件,最后归并多个有序文件。
- MapReduce 思路: 按区间起始点分桶(bucket),每个 bucket 独立排序合并,最后处理桶间边界重叠。
- 数据库方案: 如果数据在数据库中,利用 B-tree 索引按 start 排序后流式读取,只需一次扫描。
💡 实战建议: 面试官通常不会要求写出分布式代码,但希望看到你能快速识别排序是性能瓶颈,并能给出高层设计的解法方向。这在基础设施组面试中尤为常见。
题目四:字符串解码(LeetCode 394 变种)
题目描述: 给定一个编码字符串如 "3[a2[c]]",将其解码为 "accaccacc"。
TikTok 变种: 可能要求支持更复杂的语法(如自定义分隔符 {} 或 <>、支持 Unicode 字符等)。
最优解法:双栈模拟
def decode_string(s: str) -> str:
stack_num = [] # 重复次数栈
stack_str = [] # 字符串前缀栈
curr_num, curr_str = 0, ""
for ch in s:
if ch.isdigit():
curr_num = curr_num * 10 + int(ch) # 处理多位数
elif ch == '[':
stack_num.append(curr_num)
stack_str.append(curr_str)
curr_num = 0
curr_str = ""
elif ch == ']':
prev_str = stack_str.pop()
repeat = stack_num.pop()
curr_str = prev_str + curr_str * repeat
else:
curr_str += ch
return curr_str- 时间复杂度: O(max_k × n) —— max_k 为最大嵌套重复次数,n 为输入长度
- 空间复杂度: O(max_depth × n) —— 栈深度取决于嵌套层级
Follow-up:如何通用化?
面试官可能追问:"如果这变成一个微型语言解释器,你怎么抽象?"
思路方向:
- 将
[和]抽象为语法 token,支持可配置的分隔符 - 使用递归下降解析(Recursive Descent Parser)替代硬编码的栈操作
- 引入 AST(抽象语法树)节点来代表重复表达式和字符串表达式
💡 实战建议: TikTok 特别爱把栈模拟题延伸到系统设计层面。不需要深入 AST 实现细节,但思路要清晰:tokenization → parsing → evaluation 三层结构。
题目五:滑动窗口最大值(LeetCode 239 变种)
题目描述: 给定数组 nums 和窗口大小 k,返回每个滑动窗口中的最大值。
TikTok Follow-up: "如果输入是数据流,如何保证并发安全?"
最优解法:单调队列(Deque)
from collections import deque
def max_sliding_window(nums: list[int], k: int) -> list[int]:
result = []
dq = deque() # 存储索引,对应值递减
for i, num in enumerate(nums):
# 移除窗口外的元素
if dq and dq[0] < i - k + 1:
dq.popleft()
# 维护单调递减队列
while dq and nums[dq[-1]] < num:
dq.pop()
dq.append(i)
if i >= k - 1:
result.append(nums[dq[0]])
return result- 时间复杂度: O(n) —— 每个元素最多入队/出队各一次
- 空间复杂度: O(k) —— 队列最多存 k 个索引
Follow-up:并发安全的数据流方案
import threading
from collections import deque
class ConcurrentMaxWindow:
"""线程安全的滑动窗口最大值处理器"""
def __init__(self, k: int):
self.k = k
self.lock = threading.Lock()
self.dq = deque()
self.buffer = deque()
self.results = []
def push(self, value: int) -> int | None:
with self.lock:
self.buffer.append(value)
if len(self.buffer) < self.k:
return None
# 单调队列更新
while self.dq and self.dq[-1][1] < value:
self.dq.pop()
self.dq.append((len(self.buffer), value))
# 移除过期元素
if self.dq[0][0] <= len(self.buffer) - self.k:
self.dq.popleft()
return self.dq[0][1]
def get_max(self) -> int | None:
with self.lock:
return self.dq[0][1] if self.dq else None- 关键设计: 用
threading.Lock保证并发安全,每次 push 的锁持有时间 O(1),延迟极低 - 扩展讨论: 可以用 Condition Variable 控制生产者-消费者模型,或用无锁队列(lock-free deque)进一步降低延迟
三、TikTok 电面通关策略
核心特征总结
- 题库来源: LeetCode Top 100 覆盖约 70%,难度中等为主
- 核心模式: 原题 + 变种 + follow-up,考察深度而非广度
- 时间压力: 45 分钟完成 2–3 题,几乎无调试空间
- 面试官风格: 语速快,直接追问 "Can we do better?"、"What about edge cases?"
- 语言: 部分面试官可能使用中文沟通
备考优先级(从高到低)
- HashMap + Heap — Top-K、频率统计、分组聚合
- Sliding Window — 最长/最短子串、固定窗口统计
- Interval 操作 — 合并、插入、查找重叠
- Stack 解析 — 嵌套结构解码、括号匹配
- Monotonic Queue — 滑动窗口最值
- Graph BFS/DFS — 连通性、拓扑排序
- String 子序列 — 编辑距离、最长公共子序列
每道题的准备清单
在练习每一道 LeetCode 题时,确保自己能够回答以下问题:
- ✅ 最优时间复杂度是多少? 能否进一步优化?
- ✅ 空间复杂度能否降低? 有无 O(1) 空间解法?
- ✅ 边界情况有哪些? 空输入、单元素、全相同、极大值/极小值
- ✅ 如果数据量翻倍 / 变成数据流,解法还适用吗?
- ✅ 这道题在实际系统中有什么应用场景?
四、写在最后
TikTok 的电面虽然题目不偏不怪,但**"快、准、深"**的要求让很多准备不足的候选人在第一轮就被刷掉。建议你在刷题时,不只是写出 AC 代码,更要养成"写完后主动分析 + 主动优化 + 主动举例"的习惯。
准备 TikTok SDE 面试,需要一对一技术辅导和模拟面试?
👉 访问 interview-help.live 获取专业的 SDE 面试辅导服务
📩 联系我们:interview-help.live/contact — 免费技术咨询 + 模拟面试演示
我们的技术团队覆盖分布式系统、后端开发、前端、数据工程等方向,已成功帮助数百位候选人拿下 TikTok、字节、Meta、Google 等一线大厂的 Offer。
本文基于 2026 年春季最新 TikTok SDE 面试实战经验整理。市场变化迅速,建议持续关注 interview-help.live 获取更多面试面经和备考资料。
关键词:TikTok 面试、SDE 电面、Top-K 元素、最长无重复子串、合并区间、滑动窗口最大值、字符串解码、单调队列、Bucket Sort、Min-Heap、LeetCode、算法面试、面试攻略、后端开发、技术面经