Stripe OA 系统模拟题全解析 2026|Jupyter Load Balancer 五阶段递进挑战 + 完整代码
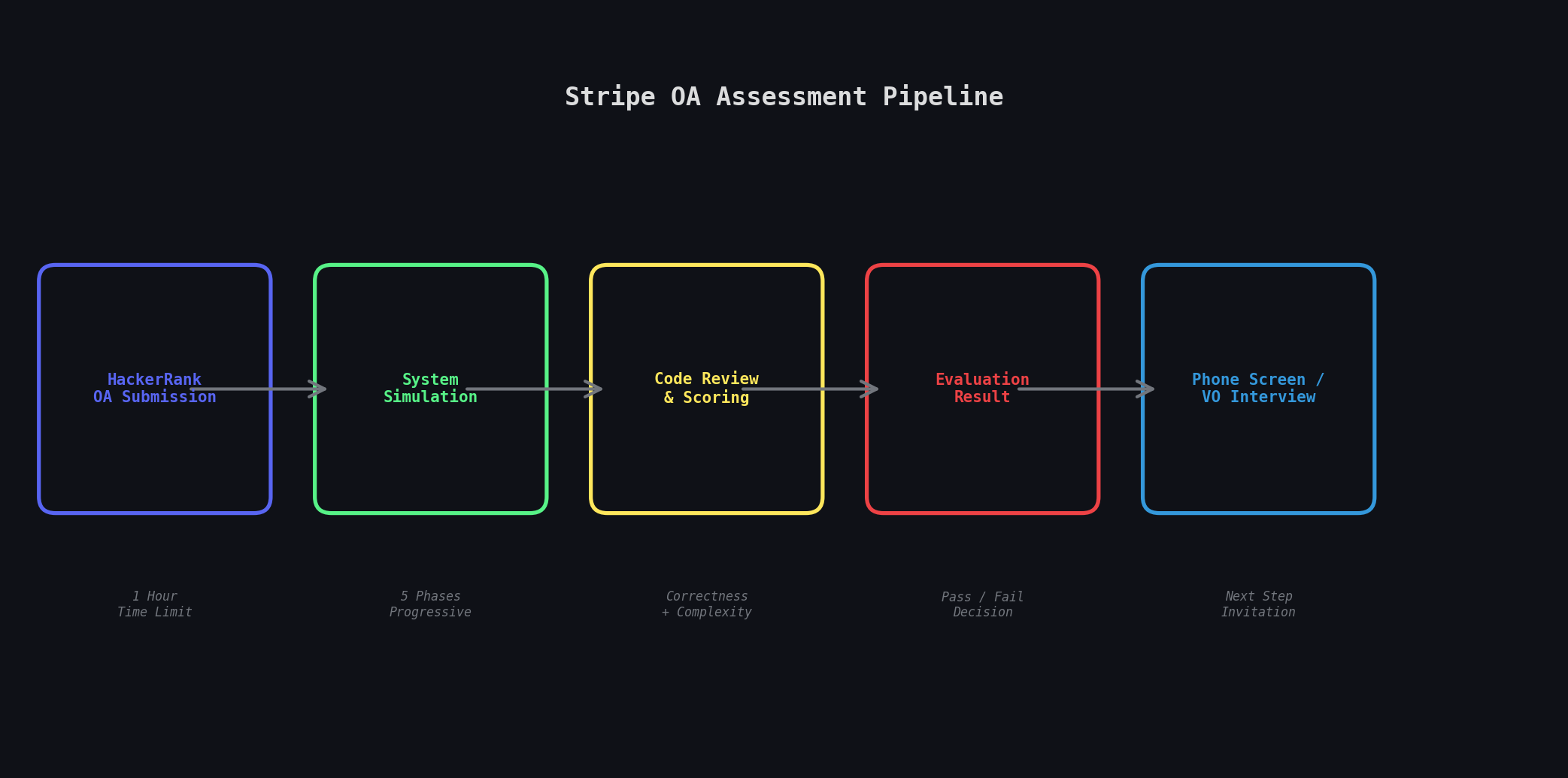
Stripe OA 流程:HackerRank 平台 → 1 小时系统模拟题 → 评估 → Phone Screen / VO。
写在前面:为什么 Stripe OA 被称为"一小时题王"
TikTok 的 OA 是一小时四道题,看似量大但每题难度适中。而 Stripe 的 OA 只有一道题——但它的复杂度远超任何 LeetCode Hard。这道题本质上是在要求你从零实现一个具备动态调度、容量控制、对象一致性和容灾恢复能力的负载均衡器原型。
题目背景来源于 Stripe Notebook 平台的实际工程场景:Jupyter 服务器集群需要处理大量并发用户请求,负载均衡器负责将每个请求路由到最优目标服务器。你的任务是实现 route_requests() 函数,完整模拟连接建立、断开、对象共享、容量限制以及服务器重启等全部行为。
题目总览
def route_requests(numTargets, maxConnectionsPerTarget, requests):
"""
numTargets: 目标服务器数量
maxConnectionsPerTarget: 每台服务器的最大连接数
requests: 请求列表,每个请求是一个字符串
返回:成功的 CONNECT 操作日志列表
格式:["connectionId,userId,targetIndex", ...]
"""请求类型:
CONNECT, connectionId, userId, objectId— 建立新连接DISCONNECT, connectionId— 断开已有连接SHUTDOWN, targetIndex— 服务器暂时下线并重路由
题目分 5 个阶段递进,每个阶段在前一阶段基础上增加新功能。
Part 1:基础负载均衡
需求
实现最基本的调度逻辑:当 CONNECT 请求到达时,选择当前负载最小的服务器。多个负载相同时,选择 index 最小的。
解法
def route_part1(numTargets, requests):
load = [0] * numTargets # 每台服务器的当前连接数
results = []
for req in requests:
parts = req.split(',')
if parts[0] == 'CONNECT':
_, connId, userId, objectId = parts
# 找到负载最小的服务器(index 最小优先)
minLoad = min(load)
target = load.index(minLoad)
load[target] += 1
results.append(f"{connId},{userId},{target}")
return results复杂度:每个请求 O(N)(找最小负载),N 为服务器数量。可以通过最小堆优化到 O(log N)。
Part 2:模拟断开连接
需求
新增 DISCONNECT 请求。系统需要维护 connectionId → server 的映射表,断开时释放对应服务器的负载。
解法
def route_part2(numTargets, requests):
load = [0] * numTargets
conn_map = {} # connectionId -> targetIndex
results = []
for req in requests:
parts = req.split(',')
if parts[0] == 'CONNECT':
_, connId, userId, objectId = parts
minLoad = min(load)
target = load.index(minLoad)
load[target] += 1
conn_map[connId] = target
results.append(f"{connId},{userId},{target}")
elif parts[0] == 'DISCONNECT':
_, connId = parts
if connId in conn_map:
target = conn_map.pop(connId)
load[target] -= 1
return results关键点:connect 和 disconnect 的更新成本都保持 O(1)(假设服务器数量不大时 min() 可以接受)。
Part 3:基于 Object ID 的路由一致性
需求
同一 objectId(即共同编辑同一个 Notebook 的用户)的请求必须路由到同一台服务器。这是 object-level consistency 约束。
解法
def route_part3(numTargets, maxConn, requests):
load = [0] * numTargets
conn_map = {} # connectionId -> targetIndex
obj_map = {} # objectId -> targetIndex
results = []
for req in requests:
parts = req.split(',')
if parts[0] == 'CONNECT':
_, connId, userId, objectId = parts
if objectId in obj_map:
target = obj_map[objectId]
else:
minLoad = min(load)
target = load.index(minLoad)
obj_map[objectId] = target
load[target] += 1
conn_map[connId] = target
results.append(f"{connId},{userId},{target}")
elif parts[0] == 'DISCONNECT':
_, connId = parts
if connId in conn_map:
target = conn_map.pop(connId)
load[target] -= 1
# 注意:不能简单清除 obj_map,因为可能还有其他连接共享该 object
return results难点:断开连接后不能直接清除 obj_map,因为同一个 objectId 可能还有其他活跃连接。需要检查该 object 是否还有活跃连接。
Part 4:服务器容量限制
需求
每台服务器最多承载 maxConnectionsPerTarget 个连接。满载时排除在候选列表外。如果所有服务器都满载,新请求被拒绝(不输出日志)。
注意:即使一个 objectId 已绑定的服务器已满,也必须拒绝——不能为了容量而牺牲一致性。
解法
def route_part4(numTargets, maxConn, requests):
load = [0] * numTargets
conn_map = {}
obj_map = {}
obj_conn_count = {} # objectId -> active connection count
results = []
def findTarget(objectId=None):
# 如果有 object 绑定,检查该服务器是否还有容量
if objectId and objectId in obj_map:
target = obj_map[objectId]
if load[target] < maxConn:
return target
return None # 绑定服务器已满,拒绝
# 常规负载均衡:找负载最小且未满的服务器
minLoad = float('inf')
target = -1
for i in range(numTargets):
if load[i] < maxConn and load[i] < minLoad:
minLoad = load[i]
target = i
return target
for req in requests:
parts = req.split(',')
if parts[0] == 'CONNECT':
_, connId, userId, objectId = parts
target = findTarget(objectId)
if target is not None:
load[target] += 1
conn_map[connId] = target
if objectId not in obj_map:
obj_map[objectId] = target
obj_conn_count[objectId] = obj_conn_count.get(objectId, 0) + 1
results.append(f"{connId},{userId},{target}")
elif parts[0] == 'DISCONNECT':
_, connId = parts
if connId in conn_map:
target = conn_map.pop(connId)
load[target] -= 1
obj_conn_count[userId] = obj_conn_count.get(userId, 0) - 1
return results复杂度:findTarget() 最坏 O(N),可通过维护一个按负载排序的集合优化到 O(log N)。
Part 5:服务器下线与连接重路由
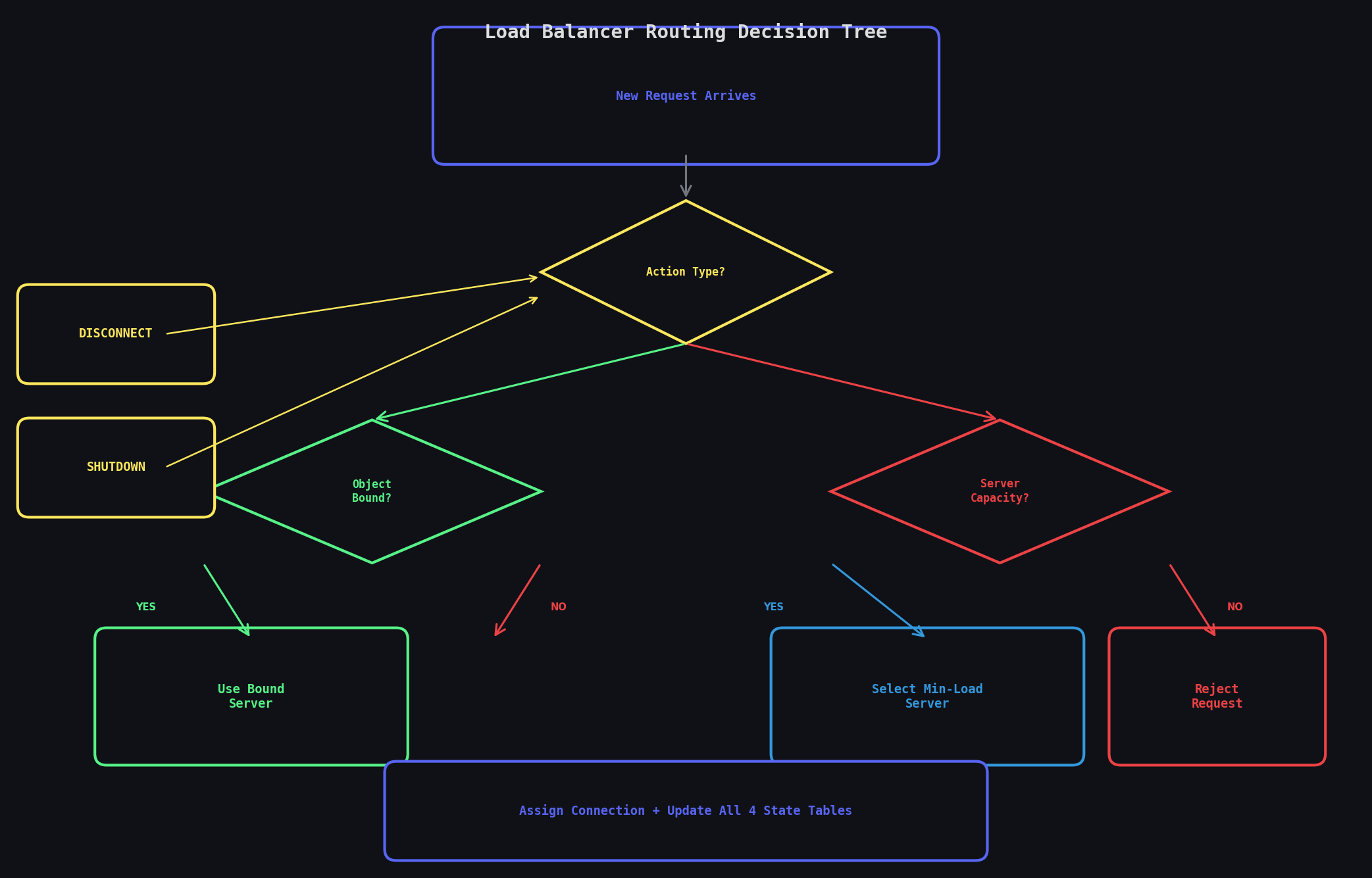
Load Balancer 核心路由逻辑:请求到达 → 容量检查 → 对象一致性约束 → 服务器分配 → 下线重路由。
需求
当收到 SHUTDOWN, targetIndex 时:
- 驱逐该服务器上所有活跃连接
- 按照之前的路由规则将它们重新分配到其他服务器
- 被重路由的连接同样记录在输出日志中
- 服务器假设瞬时重启,后续请求仍可分配到它
完整解法(5 阶段整合)
def route_requests(numTargets, maxConnectionsPerTarget, requests):
load = [0] * numTargets
conn_map = {} # connectionId -> targetIndex
obj_map = {} # objectId -> targetIndex
obj_conn_count = {} # objectId -> active count
conn_info = {} # connectionId -> (userId, objectId)
results = []
def doConnect(connId, userId, objectId):
"""执行连接操作,返回目标 index 或 None"""
target = None
# 检查 object 一致性
if objectId in obj_map:
target = obj_map[objectId]
if load[target] >= maxConnectionsPerTarget:
return None # 绑定服务器已满
else:
# 找负载最小且未满的服务器
target = -1
minLoad = float('inf')
for i in range(numTargets):
if load[i] < maxConnectionsPerTarget and load[i] < minLoad:
minLoad = load[i]
target = i
if target == -1:
return None # 所有服务器已满
obj_map[objectId] = target
load[target] += 1
conn_map[connId] = target
conn_info[connId] = (userId, objectId)
obj_conn_count[objectId] = obj_conn_count.get(objectId, 0) + 1
return target
def doDisconnect(connId):
"""断开连接"""
if connId not in conn_map:
return
target = conn_map.pop(connId)
load[target] -= 1
userId, objectId = conn_info.pop(connId)
obj_conn_count[objectId] -= 1
if obj_conn_count[objectId] == 0:
del obj_conn_count[objectId]
if objectId in obj_map and obj_map[objectId] == target:
del obj_map[objectId]
def doShutdown(targetIndex):
"""服务器下线,驱逐并重路由所有连接"""
# 收集该服务器上的所有连接
evicted = [(cid, userId, objId) for cid, (userId, objId) in conn_info.items()
if conn_map[cid] == targetIndex]
# 清除该服务器上的所有状态
for connId, userId, objectId in evicted:
del conn_map[connId]
del conn_info[connId]
obj_conn_count[objectId] -= 1
if obj_conn_count.get(objectId, 0) == 0:
del obj_conn_count[objectId]
if objectId in obj_map and obj_map[objectId] == targetIndex:
del obj_map[objectId]
load[targetIndex] = 0
# 重路由
for connId, userId, objectId in evicted:
newTarget = doConnect(connId, userId, objectId)
if newTarget is not None:
results.append(f"{connId},{userId},{newTarget}")
for req in requests:
parts = req.split(',')
action = parts[0]
if action == 'CONNECT':
_, connId, userId, objectId = parts
target = doConnect(connId, userId, objectId)
if target is not None:
results.append(f"{connId},{userId},{target}")
elif action == 'DISCONNECT':
doDisconnect(parts[1])
elif action == 'SHUTDOWN':
doShutdown(int(parts[1]))
return results复杂度分析:
- CONNECT / DISCONNECT:O(N) — 遍历找最优服务器
- SHUTDOWN:O(K × N) — K 为该服务器上的连接数,每个重路由需要 O(N)
- 空间:O(C + O) — C 为连接数,O 为对象数
核心数据结构总结
这道题需要同时维护 4 个核心状态表:
conn_map:connectionId → server index(连接位置)obj_map:objectId → server index(对象一致性绑定)target_load:server index → active count(负载统计)obj_conn_count:objectId → active connection count(对象活跃连接数,用于清理绑定)
每次操作必须保证这 4 张表的数据一致性——这是面试官考察的核心能力。
Stripe OA 备考建议
- 系统模拟类题目重在状态管理——先列出所有需要维护的数据结构,再逐个实现操作
- 递进式解题:先实现 Part 1 跑通框架,再逐层叠加功能,不要一开始就写完整代码
- 边界条件:空连接断开、重复连接、全部服务器满载、SHUTDOWN 空服务器
- 一小时内完成 5 个阶段意味着平均每 12 分钟一个阶段——速度意识至关重要
- 测试策略:每个阶段写完后用题目给的示例跑一遍,确认输出格式完全一致
💡 如果你正在准备 Stripe 的 OA,或者需要OA 代做 / 面试辅助服务来增加上岸概率,欢迎联系我们的技术团队获取免费 mock 测评:
👉 立即预约免费咨询
© 2026 interview-help.live — 专业 SDE 面试辅助平台